How Does ChatGPT Pick Its Next Word?
A probability machine for language

ChatGPT turns your message into small text pieces, then uses patterns learned from many examples to guess what piece should come next. It gives many possible next pieces different chances, then picks one and repeats the process. It does not understand like a person, but it can produce useful text by following learned language patterns.
ChatGPT writes one small step at a time. It does not pull a finished paragraph from a file. It reads the text so far, turns it into small pieces called tokens, and calculates which token is likely to come next. Then it adds one token and does the same calculation again. This loop can make a sentence, a poem, or code. The key idea is probability. The model gives each possible next token a score, then turns those scores into chances. A word that fits the context gets a higher chance. A word that does not fit gets a lower chance. Settings can make the choice more steady or more varied. That is why the same prompt can lead to different answers. This article connects to the AI & ML Basics cheat sheet and high school probability standards.
Text becomes tokens
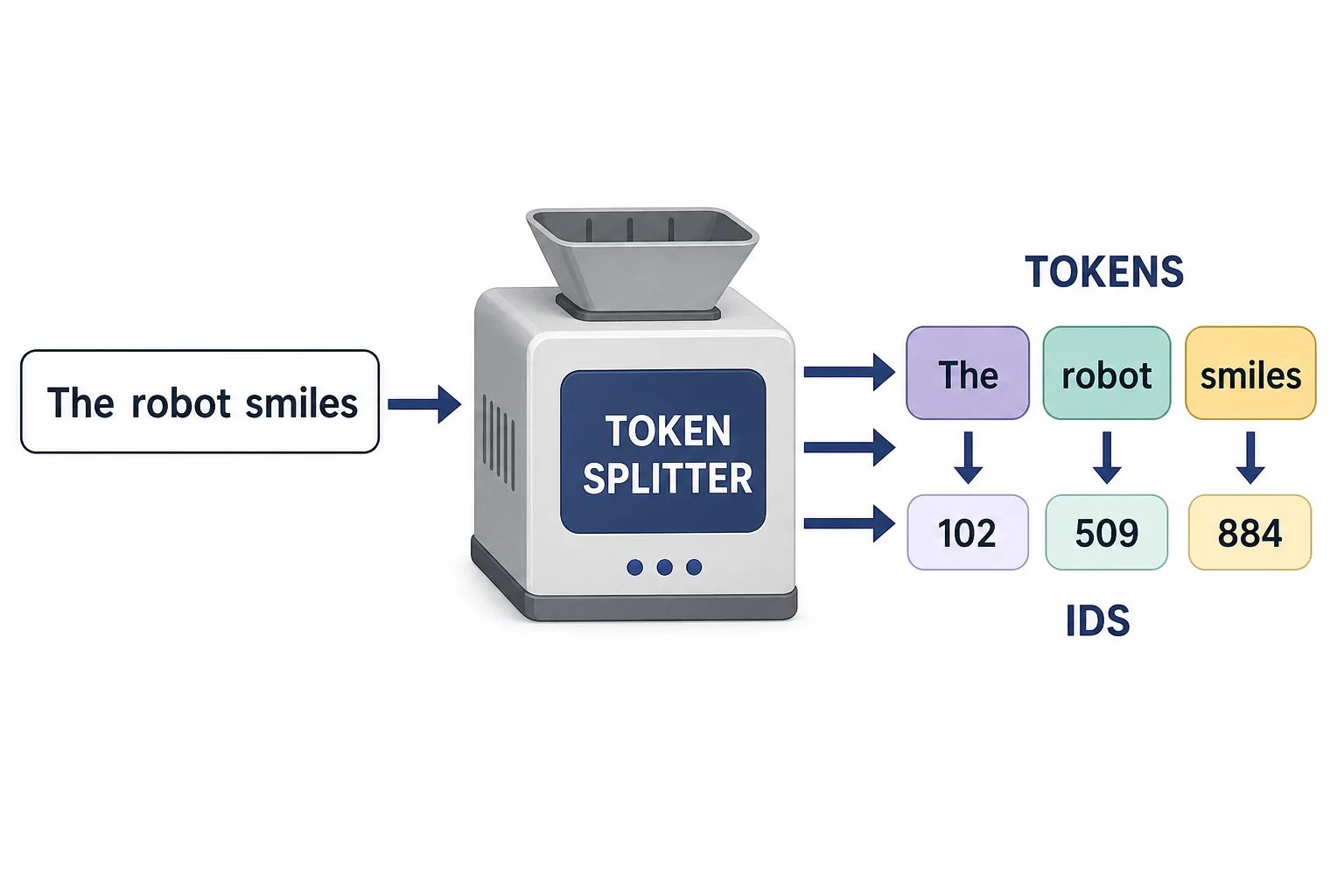
Tokens are the small pieces the model predicts.
Context changes the guess
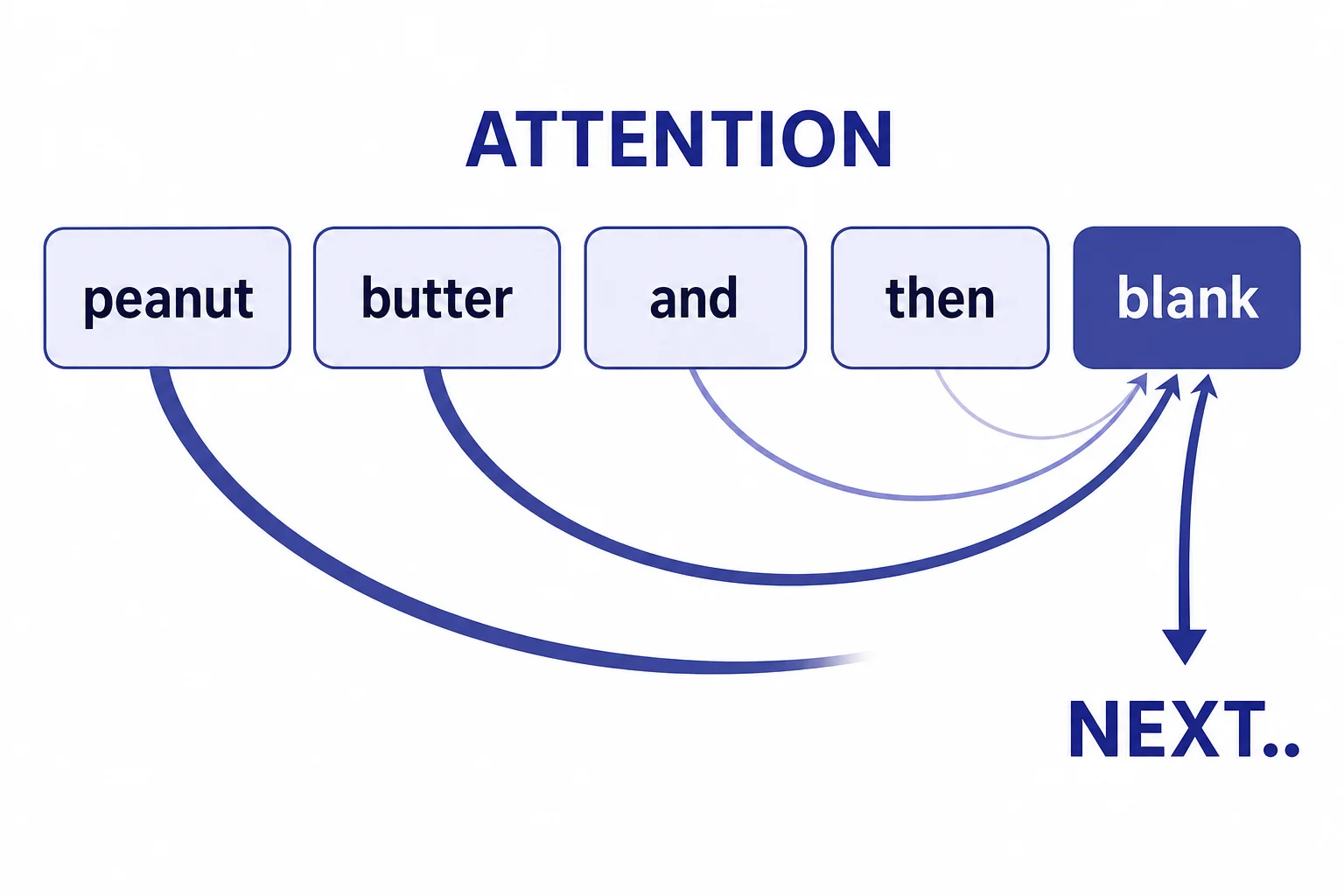
Attention is a way to weigh which earlier tokens matter.
Scores become chances
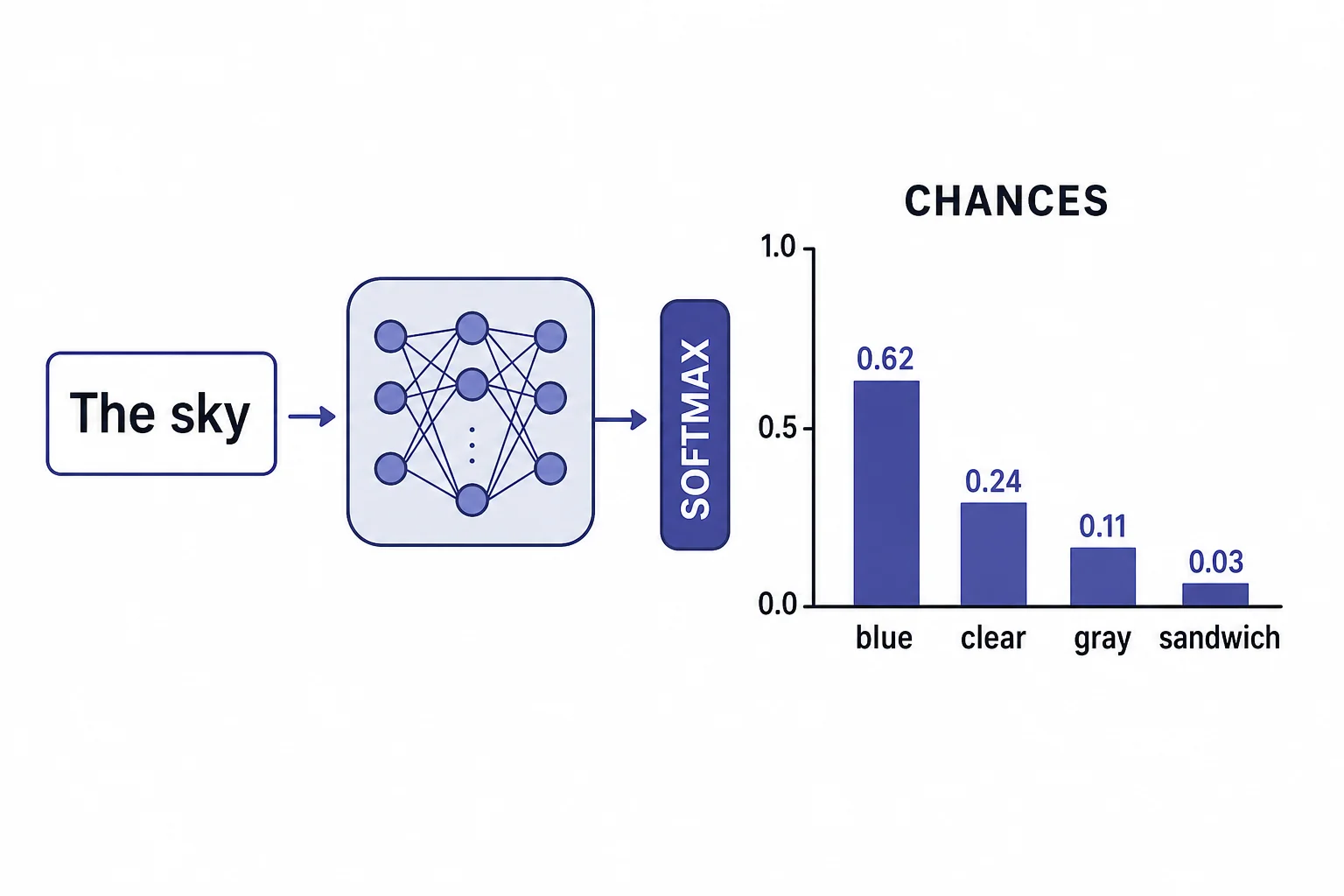
The next token is picked from a distribution of chances.
Temperature changes variety
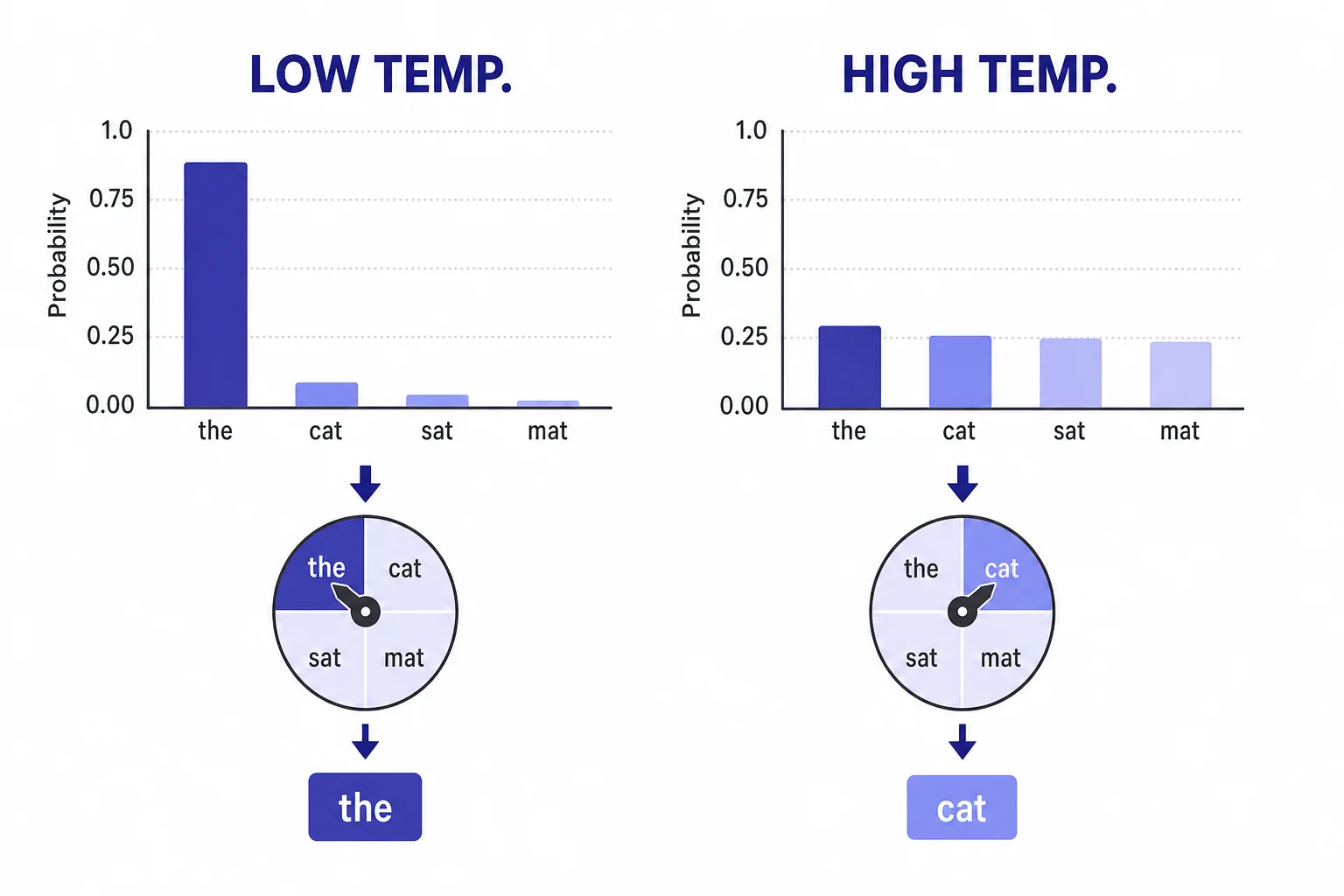
Temperature changes variety, not understanding.
One token at a time
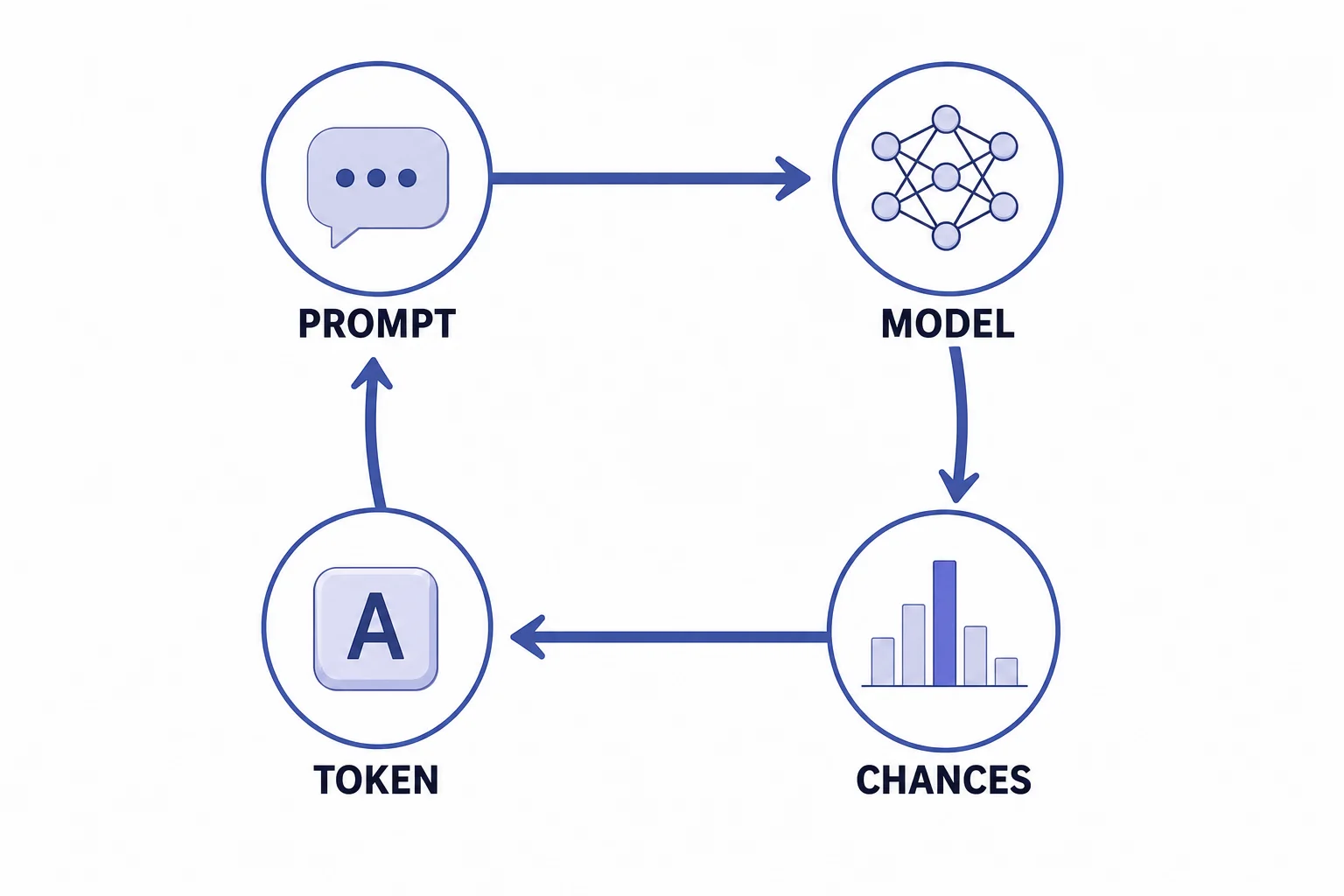
Every chosen token changes the context for the next choice.
Vocabulary
- Token
- A small piece of text, such as a word, part of a word, space, number, or punctuation mark.
- Transformer
- A type of machine learning model that uses attention to process relationships among tokens in context.
- Attention
- A method that lets a model give different weights to earlier tokens when predicting a later token.
- Probability distribution
- A list of possible outcomes with chances assigned to them, where the chances add up to 1.
- Temperature
- A sampling setting that changes how predictable or varied the next token choice can be.
- Sampling
- Choosing one outcome from a probability distribution instead of always taking the top option.
In the Classroom
Build a next word spinner
20 minutes | Grades 9-12
Students write a short prompt and list five possible next words with assigned probabilities that add to 1. They use a spinner or random number table to sample the next word several times and compare the outputs.
Compare low and high temperature writing
25 minutes | Grades 9-12
Give students the same sentence starter and two different sampling rules. One rule strongly favors the top word, while the other spreads chances more evenly. Students discuss how the outputs change and what is gained or lost.
Attention map sketch
15 minutes | Grades 9-12
Students mark which earlier words matter most for predicting a blank in a sentence. They draw thicker lines for stronger influence and explain their choices using context clues.
Key Takeaways
- • ChatGPT generates text by predicting one token at a time.
- • Tokens are small text pieces that can be words, word parts, spaces, or punctuation.
- • Transformer attention helps the model use context when ranking next token choices.
- • Temperature and sampling settings can make answers more steady or more varied.
- • A language model predicts text patterns and does not understand the way a person does.